Une fois n'est pas coutume, cet article ne sera pas (trop) orienté technique, mais fait plutôt suite à un retour d'expérience sur un projet qui se termine, et dans lequel la souplesse de OpenIDM et son côté "boîte à outils" ont permis de faire des choses qui auraient été compliquées à faire avec un autre outil (sachant que la principale solution avec laquelle je peux comparer est IBM ISIM).
Note : ceci s'applique à la version 3.1. La version 4.0 a de nouvelles fonctionnalités proches de celles que nous avons implémenté, mais n'était pas disponible au démarrage du projet.
Je vais tout d'abord poser le contexte du projet et ces spécificités, et par la suite les fonctions qui ont permis de répondre à ces demandes.
Contexte du projet
Le projet initial
A l'origine, le projet consistait simplement à faire une migration technique à partir de Sun IDM. L'environnement technique était assez courant :
- Serveur sous linux
- Repository sous Oracle de préférence (cluster Exadata)
- Connecteurs LDAP (2 root Suffix sur le même serveur)
- Gestion des comptes Active Directory
- Gestion des boîtes aux lettres Exchange
- Connecteur SAP "OLO" (On Line Ordering)
Bref, a priori, et vu les fonctions mises en oeuvre par notre société il y a 7 ans (en 2007 / 2008), la solution OpenIDM devait convenir, puisque Forgerock nous précise qu'un connecteur SAP est (ou sera) disponible.
Une particularité du client cependant : dans Sun IDM, il gère des "vrais" utilisateurs nominatifs, et des comptes de commerciaux (SFA = Sales Forces Automation) qui sont des comptes génériques, qui gèrent des périmètres géographiques, et peuvent passer d'une personne à une autre.
Dans Sun IDM, on a donc deux types d'utilisateurs, avec quasiment les mêmes attributs.
Pour la partie IHM, nous avons prévu de réécrire la partie annuaire pages blanches, et d'adapter l'interface de gestion des utilisateurs en ajoutant certains champs. J'ai testé la modification, et ça me semble jouable.
La réalité du projet
Premières réunions de cadrage et d'architecture, et là ça commence à se compliquer...
Tout d'abord, nous nous apercevons que le client n'a plus la connaissance de ce qui est en place. Les membres de l'équipe qui ont participé au projet il y a 7 ans sont partis dans d'autres sociétés, et la documentation ne semble plus à jour.
Le responsable du lancement de l'appel d'offre chez le client a également posé sa démission, et est parti avant le démarrage du projet.
Le chef de projet est assez nouveau dans la société (un an d'ancienneté), avec un rôle d'adminisrateur système Windows, et ne connaît donc pas toutes les particularités mise en place.
Nos anciens collègues qui ont mis en place sont soit partis, soit en mission en clientèle et donc difficilement mobilisables.
Jusque là, rien de trop grave, j'ai mis la main sur la documentation de l'ancien projet, ainsi que sur le code source des adaptateurs développés. On devrait s'en sortir.
Plus embêtant, la première réunion fait également état d'un autre projet d'intranet / réseau social d'entreprise (RSE), qui a plusieurs impacts sur le périmètre de notre projet :
- Il faut que chaque personne dispose d'un compte nominatif, pour pouvoir participer / poster en son nom (et pas un compte générique)
- Du coup, il faut pouvoir lier une identité personnelle avec un ou N comptes commerciaux
- Et, effet collatéral, notre projet de migration technique devient sur le chemin critique du projet de RSE, qui a une forte visibilité
Au final, on se retrouve avec un schéma des interactions qui ressemble à ça :
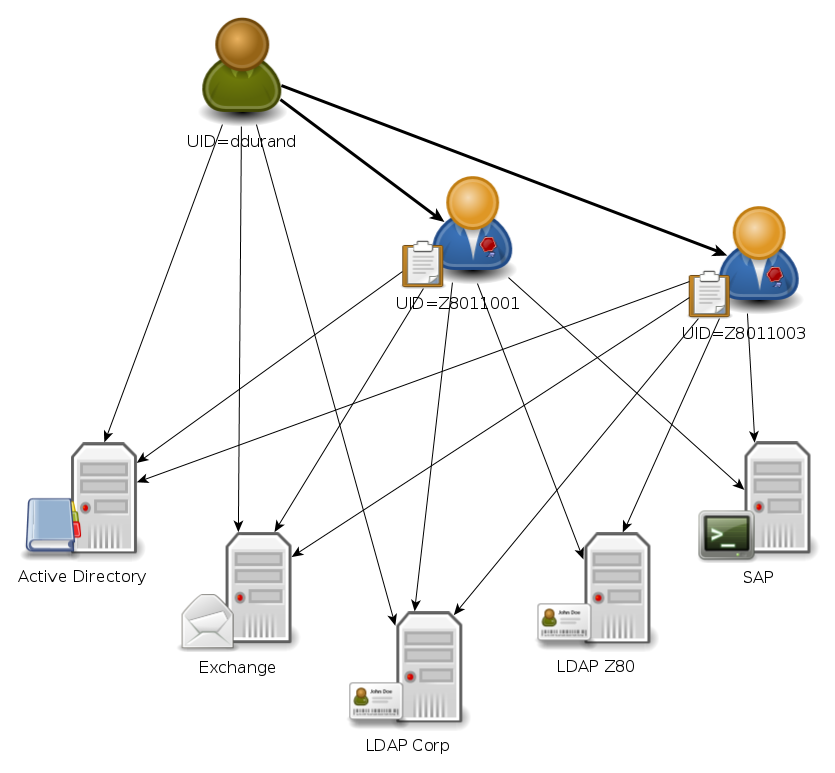
En plus, on va coupler tout cela avec un changement d'annuaire, le client voulant passer de Sun Directory Server vers autre chose, probablement OpenDJ.
A première vue, ceci n'arrange pas trop nos affaires, surtout que tout ceci démarre fin mai et que la période de congés arrive, et que nos ressources compétentes sur le sujet IAM sont très limitées. Pour tout dire, je découvre le produit OpenIDM au démarrage du projet.
Autre souci : OpenIDM 3.1 ne gère pas (encore) le multi-comptes. A priori la version 4.0 devrait le faire, mais ne sera pas disponible avant la date de mise en production.
Bref, le simple projet de migration technique se transforme en projet critique avec un gros aspect fonctionnel.
Après réflexion, une fois la galère passée, je me rends compte que nous (le chef de projet et moi-même) aurions du tirer la sonnette d'alarme et négocier un avenant pour le changement de périmètre du projet. Mais le CP était un peu jeune (en fait, c'est son premier projet au forfait en tant que CP), et moi je me pose des questions sur la faisabilité technique.
Les aspects techniques qui sont amenés par ces nouveautés :
- il faut gérer deux types d'objets OpenIDM : nominatifs (user) et SFA (sfa)
- l'application de gestion doit être entièrement réécrite de zéro, sans penser à faire évoluer l'IHM OpenIDM
Nous sommes aidés sur les choix de l'architecture à mettre en place par une société partenaire de Forgerock, Paradigmo, qui nous a guidé sur les possibilités du produit dans un premier temps, puis est intervenue sur la compilation du connecteur SAP à partir du code source.
Les choix d'orientation technique
Au final, nous sommes donc partis sur les bases suivantes :
- Un objet OpenIDM user
- Un objet OpenIDM sfa
- Le lien entre sfa et user géré via un attribut uniqueIdentifier, propre à chaque user (un numéro de séquence)
- Une application écrite en Java / Spring Framework / Thymleaf, qui utilise les capacités REST de OpenIDM
Le projet a finalement été mené à terme, avec plus ou moins de retard, du fait des évolutions fonctionnelles non prévues au départ. Cependant, ces besoins spécifiques nous ont appris pas mal de choses intéressantes sur OpenIDM, et prouvé notamment l'intérêt d'un système ouvert. Par "ouvert", je veux parler d'une volonté d'interopérabilité du produit, qui a prouvé son ouverture sur différents points :
- la possibiltié de gérer des objets différents
- l'interface REST permettant d'accéder aux différentes fonctions du produit
- le connecteur SAP scripté
- le connecteur PowerShell scripté
- la possibilité de créer ses endpoints spécifiques
Modèle d'objets
Dans la version 3.1 OpenIDM, on distingue bien les ressources (qui peuvent être cible ou source pour les comptes), et les objets gérés par OpenIDM (managed items).
Autant les données des ressorces sont déclarées dans les fichiers de paramétres (provisioner-XX.json), autant le modèle des objets internes est extensible. Par défaut on ne précise pas le schémam de données qui est utilisé, on peut donc ajouter n'importe quel attribut, puisque la plupart du temps l'objet est stocké comme un objet JSON dans la base de données du repository.
De même, on peut facilement ajouter un objet managé, ce que nous avons fait pour les objets "sfa". Il suffit de quelques lignes dans le fichier conf/managed.json pour déclarer le nouvel objet. Par exemple :
{
"onDelete" : { "type" : "text/javascript", "file" : "ui/onDelete-user-cleanup.js" },
"onCreate" : { "type" : "text/javascript", "file" : "script/sfa/onCreateOrUpdateSfa.js" },
"onUpdate" : { "type" : "text/javascript", "file" : "script/sfa/onCreateOrUpdateSfa.js" },
"properties" : [
{ "encryption" : { "key" : "openidm-sym-default" },
"name" : "securityAnswer",
"scope" : "private"
},
{ "encryption" : { "key" : "openidm-sym-default" },
"name" : "password",
"scope" : "private"
},
{ "type" : "virtual",
"onRetrieve" : { "type" : "text/javascript", "rolesPropName" : "roles", "file" : "roles/effectiveRoles.js" },
"name" : "effectiveRoles"
},
{ "type" : "virtual",
"onRetrieve" : { "type" : "text/javascript", "effectiveRolesPropName" : "effectiveRoles", "file" : "roles/effectiveAssignments.js" },
"name" : "effectiveAssignments"
}
],
"name" : "sfa"
},
On définit ainsi un objet sfa, qui aura 2 attributs encryptés, et des attributs virtuels (effectiveRoles et effectiveAssignments). On précise également les scripts utilisés lors des opération de création, modification et suppression.
Dès lors, on peut accéder aux fonctions OpenIDM via un requête REST sur l'URL http://host.openidm.test:8080/openidm/sfa
Connecteur SAP
Dans le cadre du projet, nous devons connecter plusieurs instances SAP. Forgerock propose un connecteur OpenICF, qui dispose d'exemples pour SAP R/3 et SAP HR. La version que nous voulons utiliser n'étant pas encore disponible pour OpenIDM 3.1, nous sommes repartis des sources, et avons compilé le connecteur, avec les librairies SAP JCO.
Au final, il s'agit d'un connecteur scripté de type Groovy, qui s'est révélé suffisamment souple pour arriver à nos fins, car l'interaction avec SAP passait par des appels à des RFC spécifiques développées par le client, pour alimenter des tables SAP propres au client.
On peut trouver le code source sur GitHub / OpenRock : https://github.com/OpenRock/OpenICF-sap-connector.
Le connecteur a été compilé à partir des sources, via maven. Il faut auparavant récupérer les librairies sapjco. D'après ce que j'en ai vu, les clients SAP peuvent avoir accès à ces librairies.
git clone https://github.com/OpenRock/OpenICF-sap-connector.git mvn install
L'intérêt d'un connecteur scripté est de s'adapter à quasiment toutes les situations. Au final, on utilise un script par action :
- CreateSAPWebshop.groovy : pour la création des comptes
- DeleteSAPWebshop.groovy : pour la suppression
- SchemaSAPWebshop.groovy : définition du schéma. Nous avons laissé le paramétrage par défaut
- SearchAllSAPWebshop.groovy : liste des comptes SAP
- SearchSAPWebshop.groovy : recherche / lecture d'un compte
- TestSAPWebshop.groovy : test du connecteur SAP
- UpdateSAPWebshop.groovy : mise à jour du compte
La déclaration de l'utilisation des scripts se fait dans le fichier provisioner.openicf-SAP.json :
"createScriptFileName" : "&{launcher.project.location}/script/sap/CreateSAPWebshop.groovy",
"deleteScriptFileName" : "&{launcher.project.location}/script/sap/DeleteSAPWebshop.groovy",
"schemaScriptFileName" : "&{launcher.project.location}/script/sap/SchemaSAPWebshop.groovy",
"searchScriptFileName" : "&{launcher.project.location}/script/sap/SearchSAPWebshop.groovy",
"searchAllScriptFileName" : "&{launcher.project.location}/script/sap/SearchAllSAPWebshop.groovy",
"testScriptFileName" : "&{launcher.project.location}/script/sap/TestSAPWebshop.groovy",
"updateScriptFileName" : "&{launcher.project.location}/script/sap/UpdateSAPWebshop.groovy"
Nous avons rencontré quelques soucis dans le paramétrage car le client dispose de plusieurs instances SAP, et que la documentation sur le connecteur était assez évasive sur le sujet. Au final, il s'avère que le paramètre destination doit être unique, et sert comme clé pour OpenIDM. On aura donc par exemple :
"configurationProperties" : {
"host" : "p06ci.example.com",
"user" : "OPENIDMADMIN",
"password" : secret,
"client" : "020",
"vkorg" : "0016",
"destination" : "SAP06",
.../...
}
"_id" : "provisioner.openicf/SAP06",
"operationOptions" : { },
"name" : "SAP06",
Tout ceci n'étais pas documenté (le connecteur SAP ne sera finalement disponible et validé que pour la version 4). Par contre, le support se montre réactif, et plusieurs fois nous avons pu entrer en contact direct avec l'équipe de développement, dont plusieurs membres sont français, ce qui ne gâche rien...
Connecteur Powershell
Dans la série des connecteurs scriptés, on trouve également le connecteur Powershell. Celui-ci implique l'utilisation du serveur de connecteur .Net, à installer sur un serveur Windows, et qui sert de passerelle entre OpenIDM et le monde Windows.
Une fois le serveur de connecteur .Net installé, il faut également extraite l'archive mspowershell-connector-1.4.0.0.zip dans le répertoire du serveur de connecteur.
On peut alors déclarer un connecteur Powershell, en créant un fichier conf/provisioner.openicf-powershell.json dans le répertoire du projet. Ce connecteur va préciser quels sont les scripts Powershell à utiliser pour quelles opérations.
Note : le chemin spécifié pour chaque script est celui correspondant au serveur distant.
Dans notre projet, nous avons utilisé le connecteur Powershell pour gérer des boîtes de messagerie Exchange.
Plusieurs exemples sont fournis dans les samples, et l'on peut aussi trouver sur le web des exemples de configuration pour Exchange. A ce stade, le mieux est de travailler avec les administrateurs des plates-formes Windows, qui devraient avoir la connaissance du Powershell.
Les principaux soucis que nous avons eu étaient causés par des délais de synchronisation entre Exchange et AD, avec des informations qui n'étaient pas encore présentes dans Active Directory lors de la création de la boîte mail.
Une évolution future consistera à utiliser le connecteur (ou un autre) pour gérer des boîtes Office 365, en parallèle d'une installation Exchange 'traditionnelle'.
Parmi les soucis rencontrés, on peut citer la difficulté à comprendre comment passer les paramètres entre le connecteur et OpenIDM, les problèmes liés à l'appel d'une fonction non assignée (qui propovque des exceptions), etc.
Mais au final, le connecteur fonctionne, même s'il n'est pas très rapide.
Interface REST
L'une des particularités du produit - et de toute la "stack" Forgerock, est de proposer une interface REST permettant de piloter et gérer la quasi totalité de leurs solutions. Que ce soit OpenIDM, OpenDJ ou OpenAM, tous exposent une interface permettant d'y accéder via de "simples" requêtes REST / http.
Ceci nous a permis de développer plusieurs choses autour du produit :
- Une nouvelle interface graphique, suivant la charte du client, et découplée du "moteur" OpenIDM
- Des sripts d'administration / débogage, écrits pour la plupart en shell linux
- Des scripts de reprise de données, écrits en PHP
Interface graphique
Lors de la phase initiale de la réponse à appel d'offres, j'avais testé quelques modifications sur l'interface User proposée par Forgerock. Moyennant quelques adaptations de CSS et de templates, ceci aurait pu être utilisable, dans un environnement proche du standard (un seul type d'objet User par exemple).
Le changement fonctionnel induit par l'intranet, et l'ajout d'un objet SFA, nous on forcé à faire d'autres choix, tout en restant sur le même modèle que Forgercok pour les échanges avec le "moteur" OpenIDM : l'utilisation de REST.
Par contre, l'application est assez traditionnelle, s'agissant d'une application Java, installée dans un serveur Tomcat. Nous aurions pu faire une application 100% Javascript client (comme celle de Forgerock), mais nos ressources sur le sujet - et celles du client - étaient trop peu nombreuses.
Au final, l'application fonctionne, et s'appuie pour la plupart du temps sur les endpoints fournis en standard, et pour quelques cas bien particuliers sur des endpoints développés spécifiquement, avec pour but de simplifier l'application, et d'accélérer le développement. En effet, j'ai constaté qu'il était souvent beaucoup plus rapide d'écrire un nouvel endpoint, qui accepte et renvoie des données formatées correctement, que de demander aux développeurs Java d'appeler N endpoints différents. D'autre part, certaines fonctions ne sont pas disponibles autrement que via les API, par exemple la récupération des questions de sécurité.
Scripts d'administration / débogage
Forgerock propose un ensemble de scripts shell utilisables pour "envelopper" les appels curl. De mon côté, j'avais développé un ensemble de scripts - avant de tomber sur ceux de Forgerock - qui permette notamment de tester rapidement la solution, sans devoir utiliser la console.
Dans le cadre du développement de l'application spécifique, ceci permettait rapidement de voir les effets de l'appel des différentes URL.
La plupart des scripts sont utilisés en mode GET. Par exemple, pour récupérer les objets user et sfa liés par leur attribut UniqueIdentifier, nous avions le script suivant :
$ cat getByUniqueId
#!/bin/bash
#
source env.sh
if [ -z $1 ] ; then
echo -n "UniqueID: "
read USERID
else
USERID=$1
fi
echo "--- User ---"
./getREQ managed/user/?_queryId=get-by-field-value\&field=uniqueIdentifier\&value=${USERID}\&_fields=uid,mail,uniqueIdentifier,userName,employeeNumber
ech "--- SFA ---"
./getREQ managed/sfa/?_queryId=get-by-field-value\&field=uniqueIdentifier\&value=${USERID}\&_fields=uid,mail,uniqueIdentifier,userName,employeeNumber
Ce script fait appel au script plus générique getREQ, qui lance une requête de type GET :
$ cat getREQ
#!/bin/bash
#
source env.sh
if [ -z $1 ] ; then
echo -n "Endpoint : "
read REQ
else
REQ=$1
fi
ENDPOINT=${IDMHOST}/openidm/${REQ}
echo "Endpoint : ${ENDPOINT}"
echo
curl -s --insecure --header "X-OpenIDM-Username: ${IDMUSER}" --header "X-OpenIDM-Password: ${IDMPASS}" \
--header "Content-Type: application/json" --request GET ${ENDPOINT} | python -m json.tool
Et au final, on utilise un script permettant de définir les variables d'environnement :
$ cat env.sh
#
# Environment settings
#
OPENIDM_SERVER=localhost
OPENIDM_SERVER_PORT=8080
IDMHOST="http://${OPENIDM_SERVER}:${OPENIDM_SERVER_PORT}"
IDMPASS="Passw0rd"
IDMUSER="openidm-admin"
On peut aussi par exemple utiliser un script shell pour tester l'envoi de mail via le produit :
$ cat sendMail
#
# --header "If-None-Match:*" \
#
source env.sh
if [ -z $1 ] ; then
echo -n "TO : "
read TO
else
TO=$1
fi
ENDPOINT=${IDMHOST}/openidm/external/email/?_action=send
HOST=$(hostname)
curl -X --insecure --header "X-OpenIDM-Username: ${IDMUSER}" --header "X-OpenIDM-Password: ${IDMPASS}" \
--header "Content-Type: application/json" --request POST \
--data '{"from" : "idm.admin@example.com", "to" : "'$TO'", "subject": "Test","body" : "Test message from OpenIDM server '$HOST'" }' \
${ENDPOINT} | python -m json.tool
Reprise de données
Nous avons cumulé le changement d'outil IDM avec le changement de l'annuaire LDAP, et l'introduction de nouveaux attributs sur les comptes. Ceci a parfois posé des effets de bord, voire des dommages collatéraux.
Plusieurs programmes de reprise de données ont été réalisés, en PHP, utilisant des appels aux fonctions OpenIDM via CURL. L'avantage de travaillere directement sur OpenIDM et non pas sur l'annuaire LDAP était que les données étaient du coup synchronisées dans tous les comptes qui le nécessitaient : LDAP, AD, etc.
Ce mode de fonctionnement était d'autant plus nécessaire que le modèle de données OpenIDM est fait pour être souple, au détriment de la facilité d'usage : il est difficile d'utiliser des requêtes de type relationnel entre les objets et leurs attributs, sauf à passer par X jointures...
Par exemple, lors de la phase de démarrage, il a fallu identifier tous les comptes de commerciaux (comptes SFA) non liés à un propriétaire par son attribut UniqueIdentifier, ou dont l'attribut était à 0.
Ceci a été réalisé simplement via un peu de code :
<?php
$idmHost="http://localhost:8180/openidm/";
$IDMUSER="openidm-admin";
$IDMPASS="Passw0rd" ;
$curlHeaders = array (
"X-OpenIDM-Username: ".$IDMUSER ,
"X-OpenIDM-Password: ".$IDMPASS ,
"Content-Type: application/json"
);
$idmurl=$idmHost.'/managed/sfa/?_queryId=query-all&_fields=uid,uniqueIdentifier,mail,userName,co';
$ch=curl_init($idmurl);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,TRUE);
curl_setopt($ch,CURLOPT_HTTPHEADER,$curlHeaders);
curl_setopt($ch,CURLOPT_VERBOSE,FALSE);
$result=curl_exec($ch);
$info = curl_getinfo($ch);
curl_close($ch);
$idmObjects = json_decode($result,true);
$nbObj = $idmObjects["resultCount"];
echo "Nombre de Sfa a traiter: ",$nbObj,PHP_EOL;
$nbIdNull=0;
for ( $i = 0 ; $i < $nbObj ; $i++ ) {
$uniqueId=$idmObjects['result'][$i]['uniqueIdentifier'];
if ( !isset($uniqueId) || $uniqueId == "00000000" || $uniqueId == null ) {
$nbIdNull++;
$pays = $idmObjects['result'][$i]['co'] ;
if ( isset ($idmObjects['result'][$i]['mail'] ) ) {
echo $pays ,';',$idmObjects['result'][$i]['userName'],';',$idmObjects['result'][$i]['mail'],PHP_EOL;
} else {
echo $pays,';',$idmObjects['result'][$i]['userName'],';No mail ',PHP_EOL;
}
}
}
echo "Nombre de SFA non liés : ",$nbIdNull,PHP_EOL;
La liste était ensuite envoyée dans chaque pays, où le correspondant informatique pouvait alors assigner un compte individuel aux comptes commerciaux.
Endpoints spécifiques
Comme dit plus haut, certains endpoints spécifiques ont été développés pour faciliter le développement de l'application, ou également pour permettre aux équipes Windows d'interagir avec le produit (appel d'un endpoint OpenIDM à partir d'un script PowerShell).
Parmi les endpoints spécifiques, on peut notamment en citer quelques uns, qui couvrent des besoins propres au client :
- Récupération des questions et réponses de sécurité (c'est le help-desk qui pose la question au téléphone à la personne et vérifie la réponse)
- Récupération des sites, à partir des containers de l'Active Directory
Questions de sécurité
Le mode de fonctionnement pour le "reset" de mot de passe est un peu spécial, car il n'est pas utilisé en mode Self-Service directement. En cas d'oubli, l'utilisateur appelle le support IT du pays, qui va aller sur la fiche utilisateur, et lui poser la question de sécurité.
L'utilisateur doit alors répondre à la question (par téléphone) et l'administrateur va comparer la réponse à celle affichée, puis procédera ensuite au changement de mot de passe.
Par défaut, les informations de sécurité ne sont pas récupérées, et elles sont chiffrées. Afin de pouvoir y accéder via l'application, j'ai donc développé un endpoint :
/*
* Endpoint to retreive Security Answer of a user
*
* Parametre : uid (uid utilisateur)
*
* Requete
* GET
* read (GET) : true / false
*/
/* Take the values passed in and map them to ldap attributes */
function getAns(u) {
if ( u === "" ) {
return { "resultCount" : "0", "result" : false } ;
}
var result = false;
var params = { '_queryId' : 'for-userName', 'uid' : u };
var retour = openidm.query('managed/user',params, ["uid","securityAnswer","securityQuestion","sn", "_id","password"] );
result = { "resultCount" : "1", "result" : false } ;
if ( retour != null ) {
// On a trouve un utilisateur
if ( retour.result != null && retour.result.length > 0 ) {
logger.info("[getSecAns] Result length : {}", retour.result.length);
}
else {
result = { "resultCount" : "0", "result" : false } ;
}
}
var laReponse = retour.result[0].securityAnswer ;
var laQuestion = retour.result[0].securityQuestion ;
if ( laReponse != null ) {
// Utilisation de la fonction openidm.decrypt pour récupérer la valeur en clair
var answer = openidm.decrypt(laReponse);
}
else
{ var answer = "N/A"; }
return { "question" : laQuestion, "answer" : answer } ;
}
(function(){
if (request.method === "read") {
var u = request.additionalParameters.uid;
var action = request.additionalParameters.action;
return getAns(u);
} else {
throw { code : 500, message : "Unknown request type " + request.method };
}
})();
Le script de configuration conf/customSecAns.js contient la déclaration de ce service :
{
"context" : "endpoint/getSecAns",
"file" : "script/endpoints/getSecAns.js",
"type" : "text/javascript"
}
L'appel au service se fait via l'URL :
Endpoint : http://localhost:8080/openidm/endpoint/getSecAns?uid=lsalame
{
"question": "Couleur-preferee",
"answer": "Rouge"
}
Conclusion
La grande force de OpenIDM est son ouverture, notamment l'utilisation de REST qui permet d'accéder aux fonctions de la solution, et la possibilité de développer soi-même ses propres endpoints, afin d'utiliser les API du produit.
Les connecteurs scriptés se situent également dans la même optique d'ouverture, en permettant de réaliser assez facilement des actions très spécifiques, au prix, c'est vrai, d'un développement plus lourd que pour des connecteurs pré-paramétrés.
Une des faiblesses de OpenIDM, tout au moins dans la version 3.1, se situe au niveau de la gestion des rôles. Il est moins intuitif de déclencher des provisionnements basés sur les rôles. Il est également plus complexe de définir des rôles basés sur des attributs. Encore une fois, il faut en passer par un script qui pourra utiliser les attributs de l'objet utilisateur.
En règle générale, OpenIDM semble plus adapté pour des projets dans lesquels les règles métiers ne sont pas très complexes à implémenter, avec un nombre de rôles limités. Dans le cas contraire, il faudra passer par du développement, avec l'inconvénient de perdre la visibilité des liens entre personnes et rôles.