OpenIDM est prévu pour s'installer et fonctionner en mode cluster, de manière assez facile.
Chaque instance partage le même repository, ce qui leur permet de disposer des mêmes données, la configuration étant alors partagée. Seul le repository est utilisé pour le cluster, sans autre mécanisme (pas de test de lien réseau par exemple).
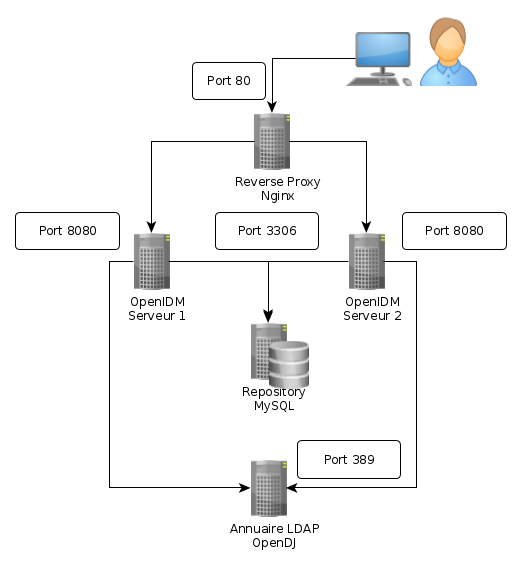
Cet article explique comment démarrer deux instances OpenIDM qui vont partager le même repository et utiliser une ressource LDAP commune (OpenDJ dans notre exemple).
Nous avons monté 5 containers Linux (lxc) :
- 10.0.3.41 (mysql) : Repository MySQL
- 10.0.3.42 (opendj) : Annuaire LDAP OpenDJ
- 10.0.3.43 (openidm1) : Première instance OpenIDM
- 10.0.3.44 (openidm2) : Deuxième instance OpenIDM
- 10.0.3.144 (openidm) : Reverse Proxy nginx
# lxc-ls -f NAME STATE IPV4 IPV6 AUTOSTART ------------------------------------------------ mysql RUNNING 10.0.3.41 - NO opendj RUNNING 10.0.3.42 - NO openidm1 RUNNING 10.0.3.43 - NO openidm2 RUNNING 10.0.3.44 - NO openidm RUNNING 10.0.3.144 - NO
Paramétrage MySQL
La base de données MySQL doit pouvoir être accédée en remote. Il faut donc autoriser des connexions à distance.
Ceci s'effectue dans le fichier /etc/mysql/my.cnf : Modifier la ligne
#bind-address = 127.0.0.1
en
bind-address = 10.0.3.41
De cette manière, la machine MySQL sera en mesure d'écouter (et de répondre) sur cette adresse IP. Il faut cependant que les utilisateurs soient autorisés à se connecter à distance. Ceci est géré lors de la création d'un utilisateur, avec une instruction GRANT par exemple :
grant all on openidm.* to usropenidm@'*' identified by 'password';
Ceci va donner les droits sur le schéma openidm pour l'utilisateur usropenidm, quelle que soit la machine (*).
On pourrait restreindre les accès à certaines adresses IP bien particulières, par exemple :
grant all on openidm.* to usropenidm@'10.0.3.43' identified by 'passw0rd'; grant all on openidm.* to usropenidm@'10.0.3.44' identified by 'passw0rd';
Paramétrage sur la première machine du cluster OpenIDM
Activation du mode cluster et position
Le paramétrage s'effectue dans le fichier conf/boot/boot.properties du projet.
S'agissant du premier noeud du cluster, on va utiliser le paramétrage suivant :
# node id if clustered; each node in a cluster must have a unique node id openidm.node.id=node1 # valid instance types for node include standalone, clustered-first, and clustered-additional #openidm.instance.type=standalone openidm.instance.type=clustered-first
Paramétrage du repository
Puisque nous utilisons une base MySQL, nous allons supprimer le fichier repo.orientdb.json, et utiliser le fichier repo.jdbc.json.
Si on ne désire pas modifier le schéma standard OpenIDM, il faut uniquement se concentrer sur la partie connection
{
"connection" : {
"dbType" : "MYSQL",
"jndiName" : "",
"driverClass" : "com.mysql.jdbc.Driver",
"jdbcUrl" : "jdbc:mysql://10.0.3.41:3306/openidm?allowMultiQueries=true&characterEncoding=utf8",
"username" : "usropenidm",
"password" : "passw0rd",
"defaultCatalog" : "openidm",
"maxBatchSize" : 100,
"maxTxRetry" : 5,
"enableConnectionPool" : true,
"connectionTimeoutInMs" : 30000
},
Paramétrage sur la deuxième machine du cluster OpenIDM
Pour effectuer la mise en route de la deuxième machine, on peut soit cloner (s'il s'agit d'une VM quelconque), soit simplement copier le contenu du répertoire projet.
Lorsque l'on configure un cluster, il faut vérifier que les fichiers de configuration soit les mêmes sur chaque instance, à l'exception du fichier boot/boot.properties.
Activation du mode cluster et position
Le paramétrage s'effectue dans le fichier conf/boot/boot.properties du projet.
S'agissant du second noeud du cluster, on va utiliser le paramétrage suivant :
# node id if clustered; each node in a cluster must have a unique node id openidm.node.id=node2 # valid instance types for node include standalone, clustered-first, and clustered-additional #openidm.instance.type=standalone openidm.instance.type=clustered-additional
Paramétrage du repository
Le paramétrage du repository doit être identique au premier serveur, puisqu'il s'agit du composant qui sera partagé entre les instances.
Configuration minimale
Si on désactive le parsing des fichiers de configuration json, il est possible de démarrer un noeud "esclave" avec un ensemble de fichiers de configuration minimal :
cd /path/to/openidm/project ls -R conf conf: boot config.properties logging.properties repo.jdbc.json system.properties conf/boot: boot.properties
Dans le fichier conf/system.properties, on va désactiver le parsing des fichiers :
# To disable the JSON file monitoring you need to uncomment this line openidm.fileinstall.enabled=false
Démarrage des instances
On peut ensuite démarrer les instances sur chaque machine :
cd /path/to/openidm ./startup.sh -p myproject
Attention : seule la configuration est stockée dans le repository.
Par contre les autres éléments du projet, par exemple des scripts JS ou Groovy qui sont en dehors du répertoire conf, ne sont pas répliqués.
De même ,les fichiers *.properties ne sont pas répliqués. Ils sont propres à l'instance. On peut donc imaginer avoir des instances travaillant sur des ports réseau différents par exemple.
Ceci peut être considéré comme un avantage ou un inconvénient :
- en cas de mise à jour, il faut répliquer les modifications sur l'autre serveur. Pour cela, on pourra utiliser un mécanisme comme rsync ou encore utiliser un gestionnaire de sources, type git ou svn.
- ceci permet cependant d'avoir des scripts et donc des comportements différents sur les deux serveurs. On pourrait donc avoir un serveur plus spécialisé dans les traitements de réconciliation, et un autre qui dispose de endpoints spécifiques qui seront utilisés par une application.
Tout dépend donc des besoins
Vérification de l'état des membres du cluster
Il existe un endpoint permettant de récupérer l'état des noeuds du cluster OpenIDM : openidm/cluster. Par exemple :
curl -s --insecure --header 'X-OpenIDM-Username: openidm-admin' --header 'X-OpenIDM-Password: openidm-admin' \
--header 'Content-Type: application/json' --request GET http://localhost:8080/openidm/cluster
{
"results": [
{
"instanceId": "node1",
"shutdown": "2015-10-13T15:59:18.478Z",
"startup": "2015-10-13T15:14:06.908Z",
"state": "down"
},
{
"instanceId": "node2",
"shutdown": "",
"startup": "2015-10-13T15:07:19.319Z",
"state": "running"
}
]
}
On constate ici que le node1 est arrêté (down). On a également une indication de la date de l'arrêt (attribut shutdown). Il est donc possible de monitorer via une sonde l'état des différents noeuds du cluster, à condition bien évidemment qu'au moins l'un des noeuds réponde aux requêtes REST !
Mise en place d'un frontal reverse proxy
Si on veut amener de la haute-disponibilité, il est nécessaire d'avoir une adresse "virtuelle" ou une URL qui ne bouge pas, et qui va jouer le rôle de reverse proxy vers les serveurs OpenIDM.
Dans le cadre de notre maquette j'ai ajouté un container LXC avec un serveur nginx qui va jouer ce rôle.
Le paramétrage du proxy est très simple :
cat /etc/nginx/sites-avaiable/openidm_proxy
## Proxy requests to OpenIDM servers
upstream app {
server 10.0.3.43:8080 fail_timeout=5s max_fails=3 ;
server 10.0.3.44:8080 backup ;
}
server {
listen 80 ;
server_name openidm.lxc.local;
# We proxy everything
location / {
proxy_pass http://app ;
}
}
On déclare un upstream que l'on appelle app, et qui est constitué des 2 serveurs openidm.
- server 10.0.3.43:8080 fail_timeout=5s max_fails=3 : c'est le serveur principal, qui va recevoir toutes les requêtes.
- server 10.0.3.44:8080 backup : c'est le serveur secondaire, en mode failover, qui recevra les requêtes si le serveur principal ne répond pas au bout de
L'explication des paramètres fail_timeout et max_fails est la suivante : le serveur est considéré indisponible s'il y a le nombre de max_fails tentatives de connexion infructueuses pendant la durée correspondant au fail_timeout. Dans notre exemple, s'il y a 3 rejets en 5 secondes, le serveur 1 sera considéré comme indisponible, et les requêtes seront routées vers le serveur 2 (backup).
Par défaut, si on ne précise pas de backup, tous les serveurs sont considérés comme primaires et nginx envoie les requêtes à l'un puis à l'autre en mode round-robin (chacun son tour).
On peut maintenant router les requêtes sur http://openidm.lxc.local, qui va gérer la répartition entre les instances OpenIDM.